Категория II#
Один ЦОД. Используются скрипты и ПРК для резервного копирования виртуальных машин и конфигурационных файлов. Резервные копии также хранятся в облачном ЦОД резервного копирования.
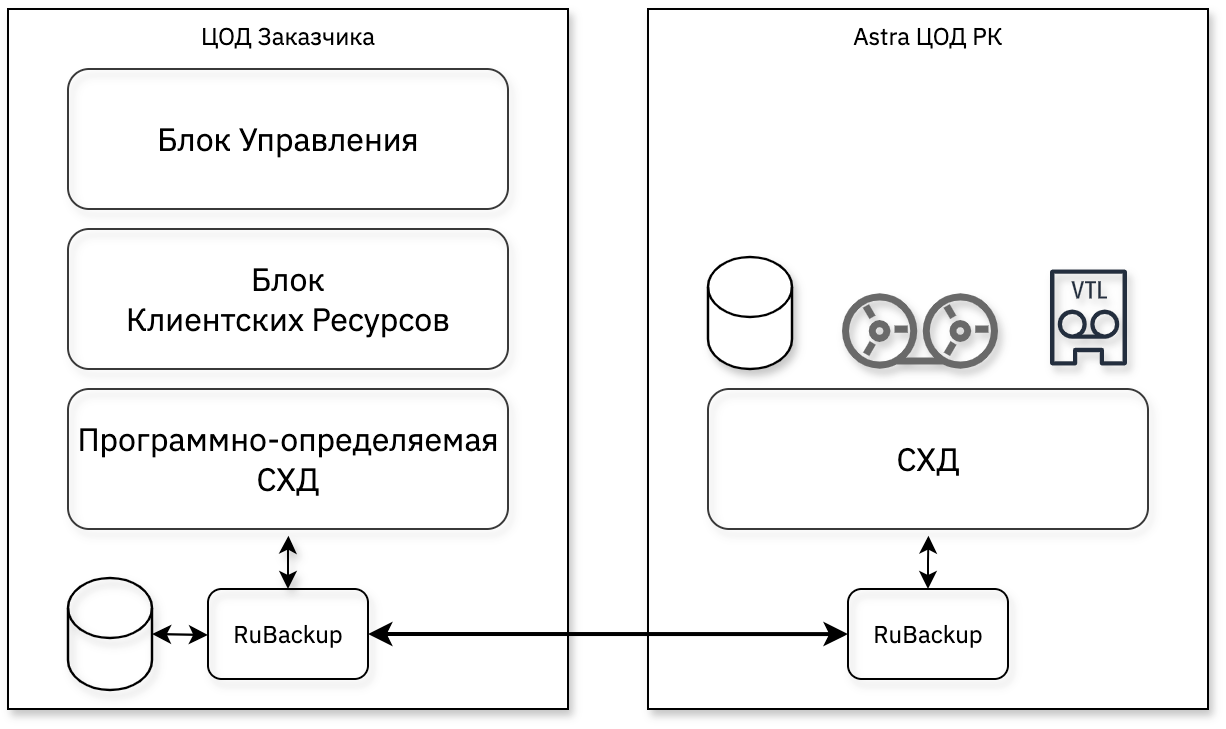
Пример элементов Disaster Recovery плана и процедур резервного копирования и восстановления для облачного центра обработки данных (ЦОД), построенного на базе Astra Infrastructure Cloud.
Виртуальные машины в ЦОД содержат различные типы приложений, такие как базы данных, серверы приложений, веб-приложения и аналитические приложения. Используются скрипты и ПО RuBackup для резервного копирования. В качестве площадки для хранения резервных копий используется облачный ЦОД резервного копирования (например Astra ЦОД РК).
Категория |
II |
|---|---|
RPO |
24 ч. |
RTO |
24 ч. |
DR |
неделя |
Доступность |
99,20% |
Архитектурная схема |
1 экземпляр - локально, резервная копия в Astra Cloud |
Standby replica данных |
Нет |
Георезервирование |
Нет |
Кластеризация |
Нет |
Отказоустойчивость инфраструктуры |
Нет |
Кластер серверов приложений |
ЦОД 1 |
Кластер СУБД |
Астра ЦОД РК |
Порог утилизации |
70% средняя часовая |
Требование к ЦОД |
Класс C (Tier2) |
Необходимые меры DR |
План |
Резервное копирование с георезервированием |
Да |
В отличии от первого варианта, использование облачного ЦОД для хранения резервных копий позволяет использовать более гибкие подходы к резервному копированию данных. Так, например, возможна синхронная или асинхронная репликация данных в ЦОД РК для последующего их резервирования с использованием ПРК.
Пример сценария репликации файловых систем и резервного копирования с использованием ПРК (СРК RuBackup):
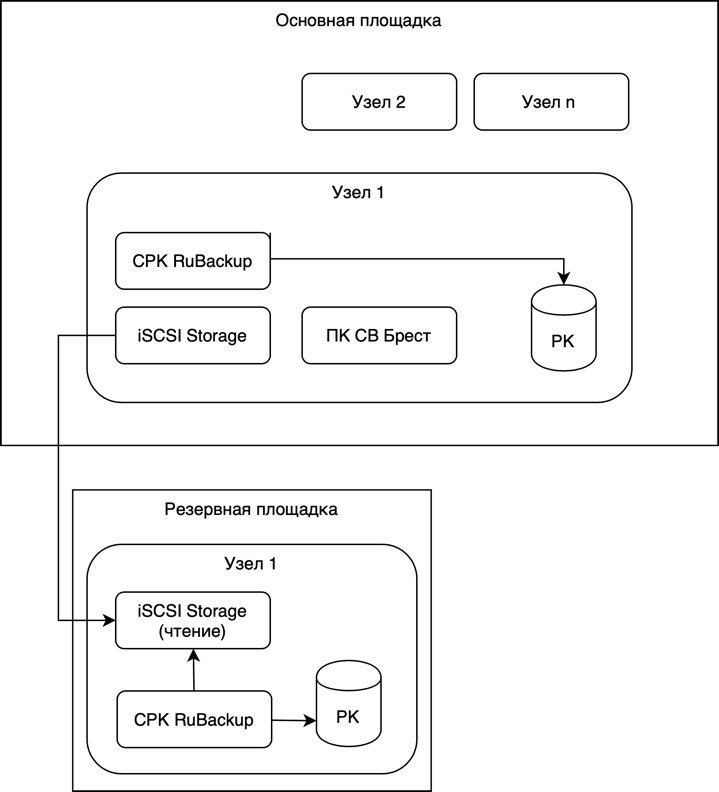
Сценарий предусматривает наличие 2-х сайтов — основной и резервный (ЦОД РК). На основном сайте развернута продуктивная среда Astra Infrastructure Cloud. Удаленный сайт предназначен для хранения резервных копий.
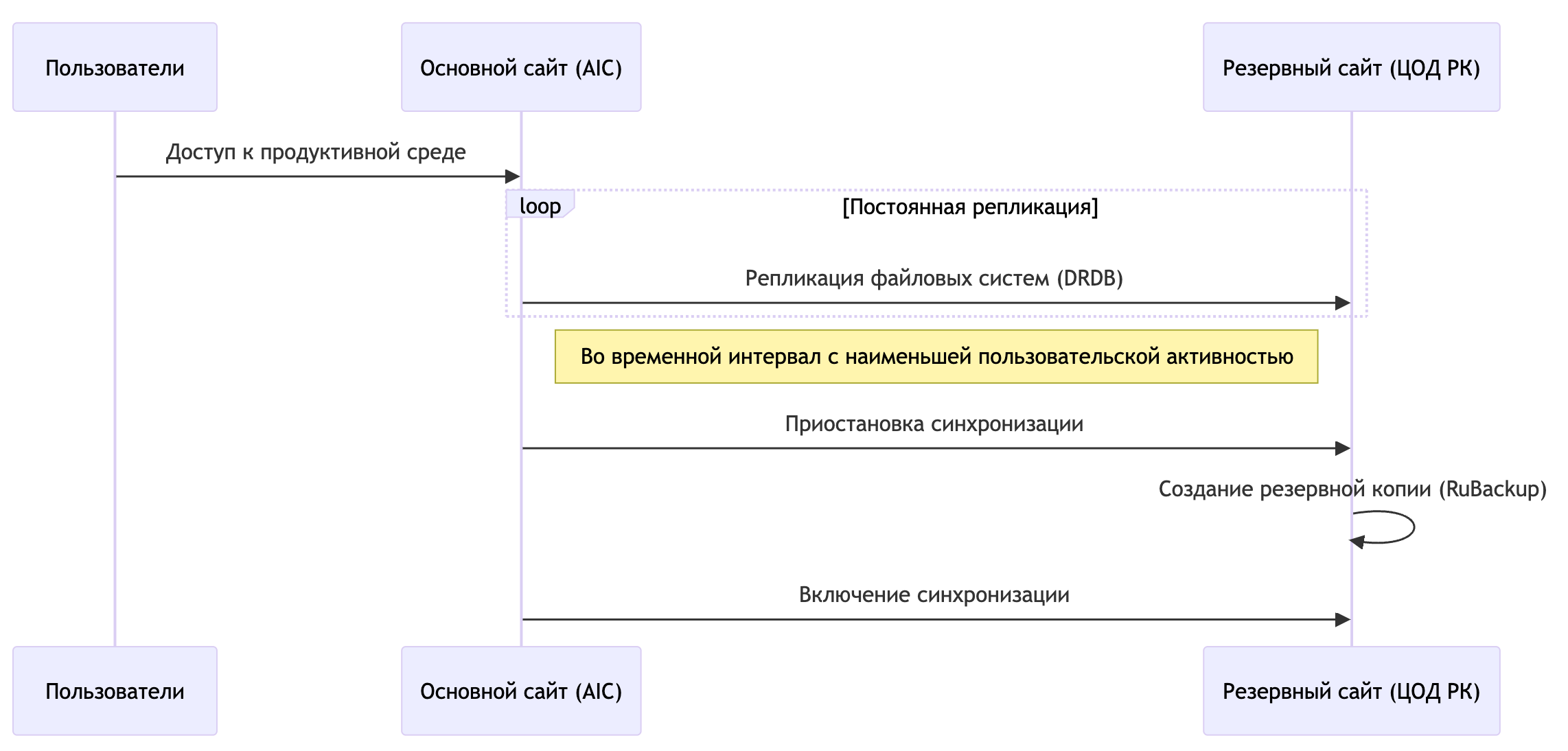
В добавление к локальным резервным копиям предусматривается создание резервных копий на удаленном сайте. Для обеспечения консистентности резервных копий на удаленном сайте, последовательность операций может быть выстроена следующим образом:
происходит постоянная репликация файловых систем узлов AIC на удаленную площадку с использованием DRDB («сетевые RAID-1 устройства»);
во временной интервал с наименьшей пользовательской активностью, для минимизации влияния на резервную копию, синхронизация между площадками приостанавливается;
выполняется создание РК на удаленной площадке с использованием механизмов ПРК;
включается синхронизация между площадками.
DRBD предъявляет определенные требования к сети, которые зависят от объема реплицируемых данных, требований к производительности и задержке.
Ключевые аспекты, которые следует учитывать при настройке сети для DRBD#
Основные требования к сети для DRBD:
Скорость сети:
рекомендуемая скорость — минимум 1 Гбит/с. Для высокопроизводительных систем, особенно с большими объемами данных или высокими требованиями к I/O, рекомендуется использовать сети с пропускной способностью 10 Гбит/с и выше;
пропускная способность — пропускная способность сети должна быть достаточной для передачи всех данных, которые записываются на устройство в реальном времени. Например, если приложения генерируют 100 МБ/с данных, сеть должна иметь пропускную способность не менее 100 МБ/с (800 Мбит/с) с учетом накладных расходов.
Задержка сети:
низкая задержка — DRBD работает лучше всего с низкой задержкой сети. Высокая задержка может значительно снизить производительность I/O операций. Желательно, чтобы задержка (round-trip time, RTT) между узлами не превышала 1-2 мс для локальных сетей;
влияние задержки — чем выше задержка сети, тем больше времени требуется для завершения операций записи, что может негативно повлиять на производительность приложений.
Резервирование и отказоустойчивость:
использование дублированных сетевых подключений (например, через bonding или teaming) для повышения надежности и отказоустойчивости;
резервные маршруты и оборудование для минимизации риска потери связи между узлами.
Изоляция трафика репликации:
разделение трафика репликации и общего сетевого трафика для предотвращения перегрузок и улучшения производительности;
использование выделенных VLAN или физически изолированных сетей для репликации данных.
Зависимость требований к сети в зависимости от объема реплицируемых данных#
Объем данных и скорость записи — чем больше объем данных и скорость их записи, тем более высокая пропускная способность требуется для сети. Например, если система генерирует и реплицирует большие объемы данных (терабайты в день), требуется сеть с высокой пропускной способностью (10 Гбит/с и выше).
Частота изменений данных — при высокой частоте изменений (например, базы данных с частыми записями) требуется сеть с низкой задержкой и высокой пропускной способностью, чтобы обеспечить своевременную репликацию всех изменений.
Тип данных — для данных, которые требуют высокой целостности и низкой задержки (например, финансовые транзакции), сеть должна обеспечивать минимальное время задержки и высокую надежность.
Пример расчета требований к сети#
Предположим, что есть приложение, которое генерирует 50 МБ данных в секунду. Требования к сети будут следующими:
Пропускная способность — 50 МБ/с данных = 400 Мбит/с. Накладные расходы сети (~20%), что дает примерно 480 Мбит/с. С учетом возможных пиковых нагрузок и резервирования рекомендуется иметь сеть с пропускной способностью не менее 1 Гбит/с.
Задержка — для обеспечения хорошей производительности задержка (RTT) между узлами должна быть минимальной, предпочтительно менее 1 мс.
Резервирование — использование дублированных сетевых подключений с пропускной способностью 1 Гбит/с каждое для обеспечения отказоустойчивости.
Рекомендации по настройке сети для DRBD#
Использование выделенных сетей — настройка выделенных сети для трафика репликации, используя отдельные VLAN или физически изолированные сети.
Мониторинг и оптимизация — регулярный мониторинг производительность сети и оптимизация настройки для обеспечения стабильной работы DRBD.
Резервирование — настройка резервных путей и сетевых подключения для повышения отказоустойчивости и минимизации рисков потери данных.
Задержки в сети могут значительно влиять на производительность приложений, особенно тех, которые зависят от частых операций чтения и записи данных.
Увеличение времени отклика (latency).
Сетевые задержки добавляют время ожидания — каждая операция чтения или записи данных через сеть добавляет время ожидания, равное задержке сети. Например, если задержка между двумя узлами составляет 50 мс, то каждая операция ввода-вывода будет задержана на 50 мс.
Кумулятивный эффект — в приложениях, которые выполняют большое количество сетевых запросов, эти задержки могут складываться, значительно увеличивая общее время отклика.
Снижение пропускной способности (throughput).
Ограничение скорости передачи данных — высокие задержки могут ограничивать эффективную пропускную способность сети, так как каждая операция передачи данных должна завершиться до начала следующей. Это особенно важно для приложений с высокой интенсивностью ввода-вывода.
Неполное использование сети — при высокой задержке данные могут передаваться медленнее, чем это возможно при низкой задержке, что приводит к неполному использованию доступной пропускной способности.
Увеличение времени транзакций.
Задержки увеличивают время завершения транзакций — в системах с распределенными транзакциями высокая задержка может значительно увеличивать время завершения транзакций, так как каждая фаза транзакции (например, подтверждение и фиксация) будет зависеть от сетевых задержек.
Влияние на согласованность данных — для приложений, требующих строгой согласованности данных, задержки могут приводить к увеличению времени согласования и проверок, что снижает общую производительность.
Воздействие на взаимодействие пользователя.
Замедление взаимодействия с пользователем — в веб-приложениях и приложениях с интерфейсом пользователя задержки могут привести к медленному отклику интерфейса, ухудшая пользовательский опыт.
Перерывы и разрывы соединений — в реальном времени приложения, такие как видеоконференции или онлайн-игры, могут страдать от перерывов и разрывов соединений из-за высоких задержек.
Увеличение времени восстановления в DRBD.
Влияние на синхронизацию данных — в DRBD высокая задержка увеличивает время синхронизации данных между первичным и вторичным узлом, что может привести к замедлению операций ввода-вывода.
Повышение времени восстановления — в случае сбоя или переключения на резервный узел высокая задержка может увеличить время восстановления данных и сервисов.
Примеры влияния задержки на приложения#
Базы данных:
влияние на производительность транзакций — для распределенных баз данных задержки могут значительно увеличить время выполнения транзакций, особенно если данные распределены между узлами, находящимися в разных географических точках.
Файловые системы:
замедление операций ввода-вывода — в распределенных файловых системах, таких как NFS или GlusterFS, задержки могут замедлить операции чтения и записи, что особенно критично для приложений, интенсивно работающих с файлами.
Веб-приложения:
увеличение времени загрузки страниц — для веб-приложений задержки могут привести к увеличению времени загрузки страниц и замедлению интерактивных элементов, таких как AJAX-запросы.
Облачные сервисы:
замедление взаимодействия с API — в облачных сервисах задержки могут замедлить взаимодействие с API, увеличивая время отклика на запросы и операции.
Рекомендации по минимизации влияния задержек#
Оптимизация маршрутов — использование оптимальных маршрутов передачи данных и технологий, таких как MPLS, для минимизации задержек.
Кеширование данных — использование кешей для данных, к которым часто обращаются, чтобы минимизировать количество сетевых запросов.
Асинхронные операции — реализация асинхронных операций ввода-вывода, чтобы уменьшить влияние задержек на производительность приложений.
Сжатие данных — сжатие данных перед передачей по сети для уменьшения объема передаваемых данных и ускорения передачи.
Управление качеством обслуживания (QoS) — настройка QoS для приоритизации критически важного трафика и минимизации задержек для важных приложений.
Понимание и управление сетевыми задержками критически важно для обеспечения высокой производительности распределенных приложений и систем.