Средства мониторинга#
Для отслеживания работы AIC используется ПО Astra Monitoring входящее в бКОР.
Astra Monitoring — платформа сбора и анализа информации о состоянии узлов IT-инфраструктуры с целью их диагностики, своевременного обнаружения неполадок и повышения стабильности работы. Платформа масштабируема и может охватывать как несколько hardware устройств, например, с SNMP интерфейсом, так и географически распределенные сети с тысячами высоконагруженных нод.
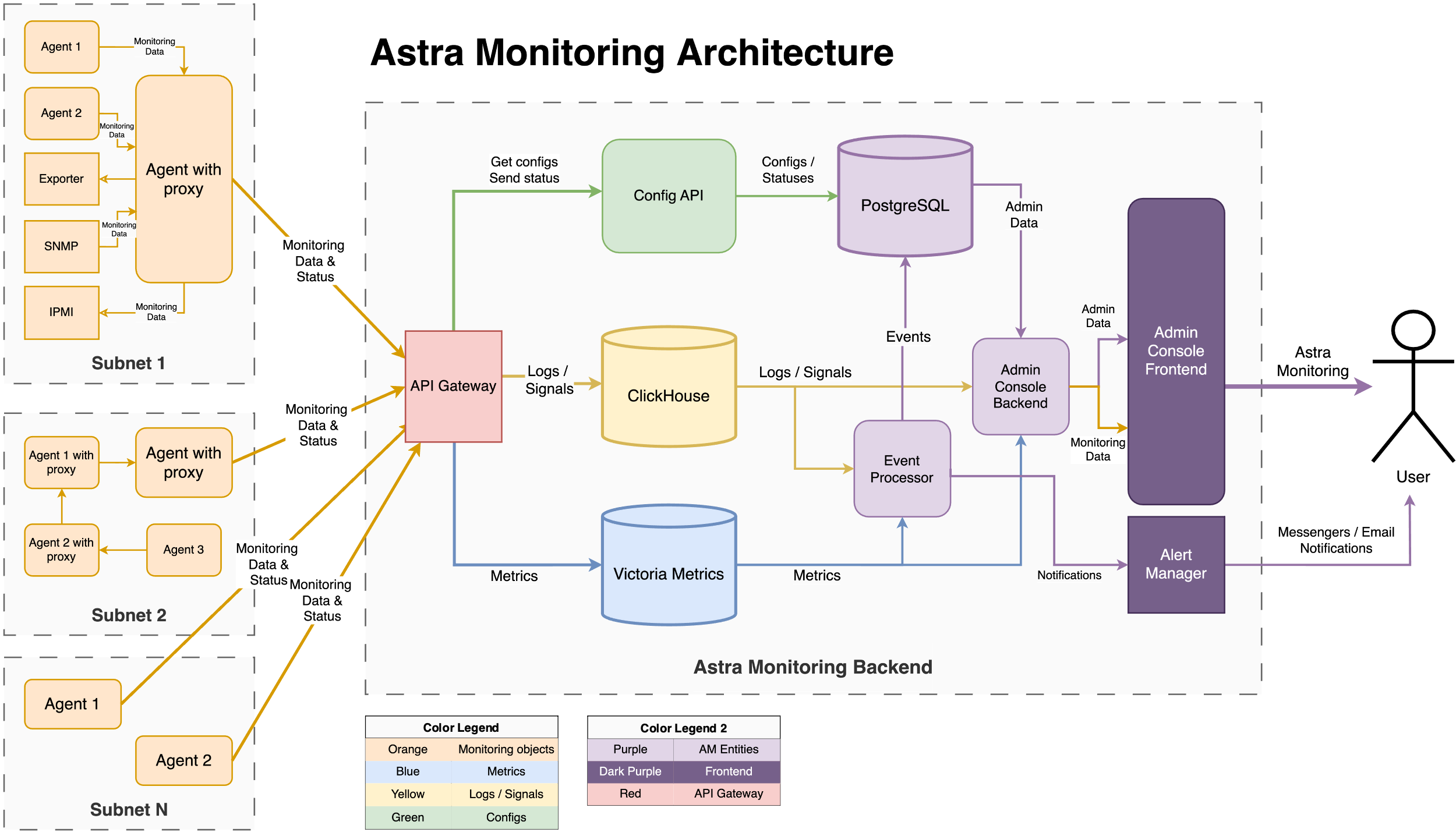
Техническая реализация строится на взаимодействии двух частей — клиентской, выполняющий непосредственный сбор диагностической информации, и центральной, отвечающей за обработку полученных данных. На клиентской части с объектов мониторинга собираются метрики, логи и сигналы, которые сохраняются в центре обработки и превращаются в события, несущие полезную информацию о возникающих состояниях объектов наблюдения.
Возможности Astra Monitoring:
сбор метрик, логов и сигналов с узлов IT-инфраструктуры;
хранение диагностической информации в центре обработки;
отображение собранной информации в панели администратора;
создание событий при изменении состояний объектов наблюдения;
оповещение пользователей по различным каналам связи.
Компонентная схема Astra Monitoring:
Клиентская часть Платформы Мониторинга#
Объект мониторинга — источник диагностической информации. Информация о наблюдаемой подсети/локальной сети предоставляется только объектами мониторинга, которые зарегистрированы в AM. Объект является отображением ноды/узла/сервера/устройства с уникальным FQDN/IP-адресом в рамках подсети/локальной сети. Для сбора данных с объекта используются его интерфейсы: сущности, описывающие правила получения и обработки данных с источника, располагаемого на объекте. Интерфейсов можно определять сколько угодно — главное задать правила обработки входящего потока байт.
Примеры интерфейсов:
exporter — HTTP сервер, предоставляющий метрики в prometheus формате;
snmp-trap — устройство, отправляющее SNMP traps, в интерфейсе описаны правила парсинга приходящего трапа;
snmp-poll — устройство, предоставляющее порт для сбора информации по протоколу SNMP, в интерфейсе описаны правила обработки;
ipmi — IPMI устройство;
http — произвольные HTTP запросы (обычно с JSON в теле), для которых определены правила обработки в сообщение.
Агент — основная компонента сбора и предоставления диагностической информации в рамках отдельного сервера/хоста.
Технически, агент является оркестратором процессов — он запускает экспортеры и vmagent для сбора метрик, vector для сбора логов, Signals Adapter для сигналов. Агент выполняет наблюдение за их состоянием и исправление возникающих проблем. Также он автоматически регистрируется в AM, предоставляя информацию о наблюдаемом хосте, способен удаленно настраиваться.
Агент состоит из нескольких внутренних модулей (managers), каждый из которых используется для своей задачи:
Exporters Manager.Отвечает за запуск экспортеров в отдельных процессах ОС, за их контроль и настройку. Экспортер — приложение, собирающее информацию и представляющее ее в виде prometheus метрик. Обычно запускается несколько экспортеров, так как каждый отвечает за сбор информации только о конкретном продукте или части системы. Например,
systemd-exporterпредоставляет метрики только о работеsystemd,node-exporter— общую информацию об ОС, и так далее;Metrics Manager. Настраивает и запускает
vmagentдля сбора метрик с экспортеров.vmgentпотребляет мало ресурсов, при этом способен собирать метрики с огромного количества источников, модифицировать лейблы и локально кэшировать собранные данные при недоступности бэкенда. Помимо экспортеров, запущенных Exporter Manager, vmagent на агенте может собирать метрики с любого другого экспортера при соответствующей настройке;Logs Manager. Настраивает и запускает
vectorдля сбора логов. Он поддерживает большое количество источников и способен трансформировать логи перед отправкой, а также сохранять в локальном буфере при ошибках отправки. Настройка и сбор логов с произвольных источников выполняется путем предоставления сторонних файлов конфигурации дляvector. Агент принимает собранные сvectorлоги для их обработки и подготовки к отправке в бэкенд;Signals Manager. Настраивает и запускает Signals Adapter для получения сигналов. Адаптер использует два сервера — UDP для приема SNMP-traps и HTTP, представляющий API для загрузки сигналов со сторонних клиентов. Сигналы принимаются адаптером, обрабатываются на основе настраиваемых правил (актуально для SNMP) и отправляются в агент. Агент производит подготовку пришедших данных к отправке в бэкенд;
Proxy Manager. Настраивает и запускает
vmauthдля агрегации всех входящих на агента запросов от других агентов. Это опциональная функция, так как агент может взаимодействовать с бэкендом напрямую. Каждый агент отправляет запросы к Config API, которые в данном случае проксируютсяvmauthна бэкенд. Также агенты присылают диагностическую информацию, которая сначала собирается в vmagent, vector и Signals Adapter на проксирующем агенте, а затем отправляется на бэкенд / следующий прокси;Watcher & Configurator. Контролирует взаимодействие с Config API, расположенном на бэкенде AM. Выполняет регистрацию при запуске, позволяет удаленно настраивать агент, предоставляет информацию о работоспособности всех его модулей.
Server. HTTP сервер, который используется для предобработки логов от vector перед отправкой в бэкенд и для healthcheck запущенного агента.
Центральная часть Платформы Мониторинга#
Получение данных#
Для взаимодействия с коллектором AM Backend предоставляет HTTP(S) API. Технически, это API Gateway, который распределяет запросы по нужным микросервисам в зависимости от пути HTTP запроса. AM Backend и коллектор могут располагаться как в одной локальной сети, так и в разных. Коллекторов, работающих с одним AM Backend, может быть несколько — их количество ограничено только доступными ресурсами. В качестве API используется vmauth — решение для балансировки нагрузки из экосистемы Victoria Metrics, которое обладает простой установкой и конфигурацией.
Хранение данных#
Victoria Metrics: хранение метрик.
Victoria Metrics — NoSQL база данных, специализированная для эффективного хранения метрик и временных рядов. Она используется для полной замены Prometheus из-за явных недостатков последнего при росте объема хранимых данных. VM предоставляет язык запросов MetricsQL, который является расширением языка PromQL и используется для получения и агрегирования метрик. Также эта БД способна горизонтально масштабироваться, что позволяет использовать ее для хранения и обработки огромного объема данных.
Метрики в Victoria Metrics попадают напрямую из vmauth.
ClickHouse: хранение логов и сигналов.
ClickHouse — NoSQL-база данных колоночного типа, оптимизированная для хранения больших объемов разнотипных данных. Основная сфера применения — OLAP (Online analytical processing) запросы, целью которых является анализ данных, создание отчетов, графиков и дашбордов. База данных имеет свой SQL-подобный язык запросов с широким функционалом, способна горизонтально масштабироваться.
Логи и сигналы сначала попадают в микросервис ClickHouse Adapter. Этот сервис предоставляет API для записи данных в ClickHouse — преобразует пришедший JSON в поля SQL запроса и формирует батч.
PostgreSQL: хранение внутренних сущностей.
PostgreSQL — реляционная база данных, обладает широким функционалом, а главное — поддержкой JSON, что сильно облегчает задачу хранения внутренних сущностей.
Внутренние сущности — данные, которые не относятся непосредственно к диагностической информации. В основном, это конфигурация различных компонент — объектов мониторинга, коллекторов, Event Processor. Также там хранятся события и лейблы.
Состояния наблюдаемых объектов
Astra Monitoring предоставляет два варианта получения информации о наблюдаемом объекте — состояние и события. Состояние представляет из себя диагностическую информацию в «сыром» виде, в то время как события — сгенерированные на основе этой информации сущности, необходимые для оповещения о наступлении определенных состояний.
События о наблюдаемых объектах
События создаются на основе приходящей в AM диагностической информации. Смысл событий — выделить из большого потока данных состояния, имеющие ценность в контексте наблюдения за жизнеспособностью объектов. Они могут быть как с положительным окрасом — сообщать о запуске сервиса, успешно проведенной миграции или завершенном авто тестировании нового релиза, так и с отрицательным — сигнализировать о высоком потреблении ресурсов, аномально большом количестве запросов или о падении значений метрик ьизнеса.
Пользовательский интерфейс
Компоненты:
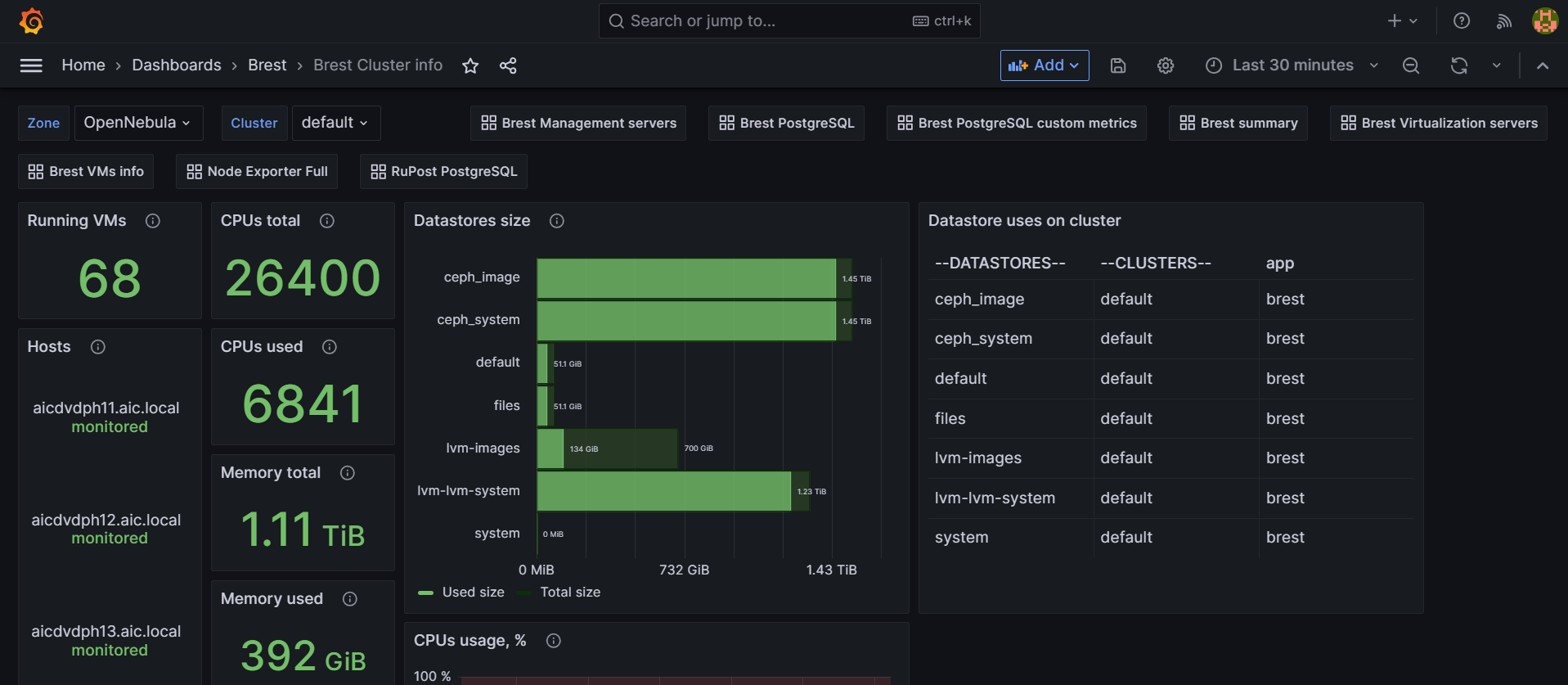
модуль визуализации метрик и логов построен на базе программного продукта Grafana, представляет из себя набор представлений данных и интерфейс анализа логов;
интерфейс управления — Admin UI. Предназначен для добавления объектов мониторинга, а также для просмотра информации о событиях по объектам мониторинга;
Keycloak. Обеспечивает аутентификацию пользователей, поддерживает интеграцию с внешними системами аутентификации и каталогами пользователей (LDAP).
Пользовательский интерфейс позволяет визуализировать собранные данные, отображать метрики в виде индикаторов и графиков, выделять и представлять пользователю информацию об обнаруженных на объектах мониторинга проблемах, добавлять объекты мониторинга в Платформу АМ или удалять их и т.д.
Веб-интерфейс Astra Monitoring: