Категория III#
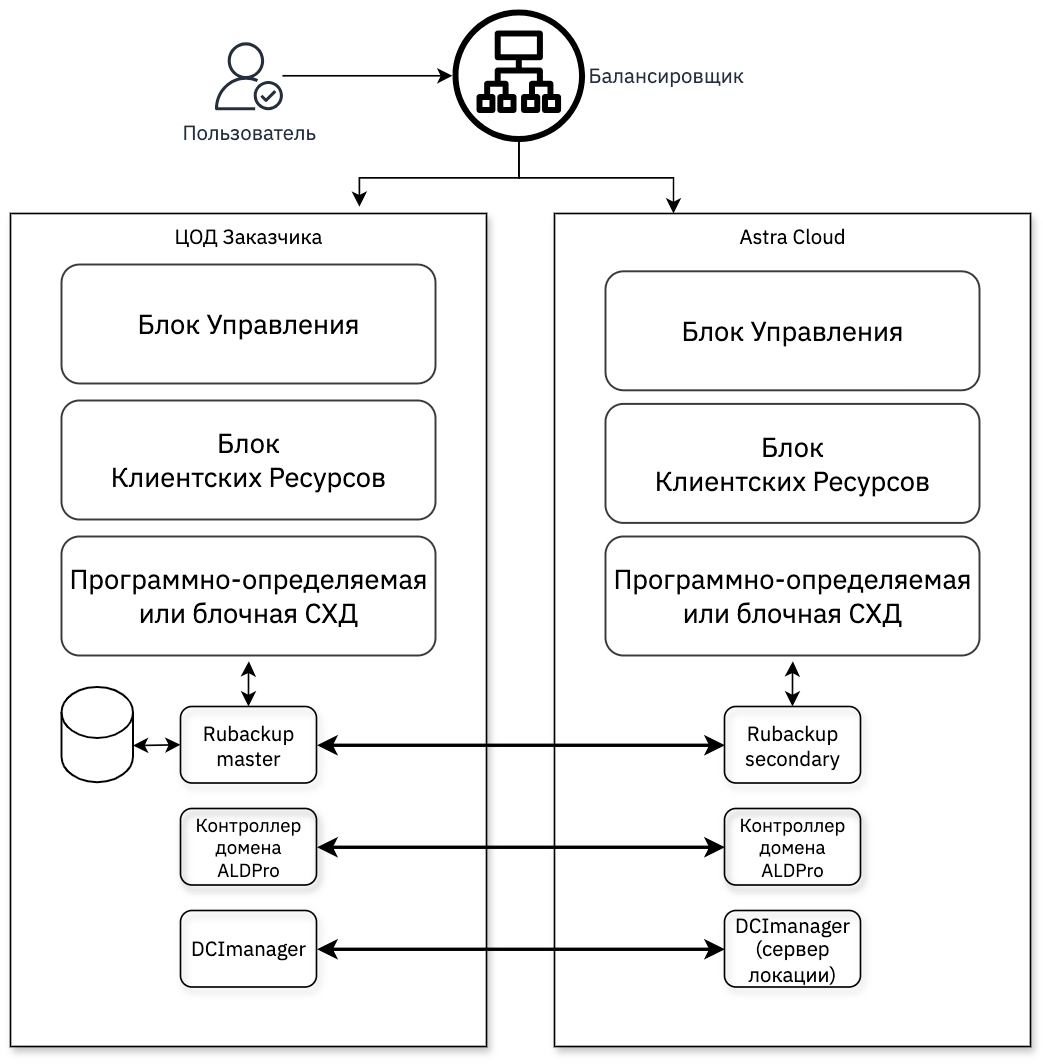
Конфигурация Active-Passive. Один основной ЦОД заказчика. Зарезервированные ресурсы в облачном ЦОД для запуска виртуальных машин в случае аварии в ЦОД заказчика. Резервные копии также хранятся в облачном ЦОД.
Категория |
III |
|---|---|
RPO |
2-8 ч. |
RTO |
4 ч. |
DR |
4 ч. |
Доступность |
99,70% |
Архитектурная схема |
Active-Passive (Гибрид Cloud) AIC + Astra Cloud |
Standby replica данных |
Нет |
Георезервирование |
Да |
Кластеризация |
Нет |
Отказоустойчивость инфраструктуры |
ЦОД 1 и ЦОД 2 |
Кластер серверов приложений |
ЦОД 1 private |
Кластер СУБД |
Астра ЦОД public КИИ |
Порог утилизации |
60% средняя часовая |
Требование к ЦОД |
Класс В (Tier3) |
Необходимые меры DR |
Да |
Резервное копирование с георезервированием |
Да |
Данный подход позволяет еще больше увеличить доступность сервисов и минимизировать время простоя, по сравнению с двумя предыдущими вариантами.
Основные режимы использования#
хранение РК в облачном ЦОД для последующего восстановления в основном ЦОД;
репликация данных в облачный ЦОД для последующего создания РК и их восстановления в основном ЦОД;
репликация данных в облачный ЦОД для повышения надежности работы сервисов с возможностью их запуска в облачном ЦОД при возникновении проблем с доступов к основному ЦОД.
Первые два режима использования подробно рассматривались в разделах Категория I и Категория II.
Для обеспечения запуска сервисов в запасном облачном ЦОД необходимо предусмотреть и обеспечить выполнение следующих процедур:
cоздание дополнительного инстанса(ов) контроллера домена ПКД в облачном ЦОД (может потребоваться для выполнения действий по восстановлению с доменной учетной записью);
синхронизация данных с основного на резервный ЦОД;
создание сценариев по запуску сервисов в облачном ЦОД;
настройка сетевого окружения, в том числе proxy серверов, для ручного или автоматического переключения клиентского трафика на резервный облачный ЦОД;
установка менеджера локаций DCImanager из состава AIC в облачном ЦОД для мониторинга состояния оборудования и выполнения превентивных действий плана аварийного восстановления (опционально).
Облачный центр обработки данных (ЦОД) построен на базе ПВ и установлен на трех узлах. Эти узлы содержат различные типы приложений, включая базы данных, серверы приложений, веб-приложения и аналитические приложения. На серверах также установлены ALD Pro для аутентификации и авторизации, и RuBackup для резервного копирования.
Для обеспечения непрерывности бизнеса необходимо разработать План аварийного восстановления (DRP), а также процедуры резервного копирования и восстановления для виртуальных машин и системного ПО. DRP должен соответствовать целевым показателям точки восстановления (RPO) в 8 часов и времени восстановления (RTO) в 4 часа. Также необходимо учитывать наличие резервного ЦОД, работающего в режиме ожидания, с пропускной способностью передачи данных между ЦОДами 1 Гбит/с.
Пример элементов плана аварийного восстановления#
Требования:
обязательные:
резервное копирование критически важных данных баз данных не реже чем каждые 8 часов;
резервное копирование конфигураций системного ПО не реже чем каждые 8 часов;
процедуры восстановления, обеспечивающие восстановление критически важных данных и системного ПО в течение 4 часов;
интеграция ПРК с существующей инфраструктурой для автоматического резервного копирования и восстановления;
репликация резервных копий в резервный ЦОД с пропускной способностью 1 Гбит/с.
желательные:
уведомления и отчеты о статусе резервного копирования и восстановления;
возможность восстановления данных из резервных копий без значительного простоя;
проверка и тестирование процедур восстановления не реже чем раз в месяц.
возможные:
интеграция с другими инструментами резервного копирования и восстановления;
оптимизация процесса резервного копирования для уменьшения времени и объема данных.
Процедуры резервного копирования#
Резервное копирование баз данных:
использование ПРК для создания резервных копий баз данных каждые 8 часов;
bash-скрипты для автоматизации процесса резервного копирования и выполнения snapshot’ов данных.
Резервное копирование системного ПО:
создание резервных копий конфигураций ALSE, ПКД и ПВ каждые 8 часов с помощью ПРК;
автоматизация процесса с помощью bash-скриптов для регулярного создания архивов конфигурационных файлов и базы данных.
Репликация данных:
использование ПРК для репликации резервных копий в резервный ЦОД;
настройка задач передачи данных с использованием утилит Linux (
rsync,scp) для синхронизации данных между ЦОД.
Процедуры восстановления#
Восстановление баз данных:
запуск ПКД для восстановления данных из последней резервной копии;
проверка целостности восстановленных данных и запуск баз данных.
Восстановление системного ПО:
восстановление конфигураций ALSE, ПКД и ПВ с помощью ПКД;
перезагрузка сервисов и проверка корректности работы системного ПО.
Тестирование восстановления:
ежемесячное тестирование процедур восстановления для проверки их эффективности и актуальности;
создание отчетов о результатах тестирования и внесение необходимых корректировок в процедуры.
Реализация#
Шаги по реализации резервного копирования и восстановления:
настройка ПКД:
установить ПКД на всех узлах основного и резервного ЦОД;
настроить ПКД для автоматического создания резервных копий баз данных и конфигураций системного ПО каждые 8 часов;
создание bash-скриптов:
разработать bash-скрипты для автоматизации процесса резервного копирования:
снятие snapshot’ов баз данных;
создание архивов конфигурационных файлов;
настроить
cronдля регулярного выполнения скриптов;
репликация данных в резервный ЦОД:
настроить ПКД для репликации резервных копий в резервный ЦОД;
использовать утилиты Linux (
rsync,scp) для передачи данных между ЦОДами с пропускной способностью 1 Гбит/с;
процедуры восстановления:
разработать скрипты для автоматического восстановления баз данных и системного ПО из резервных копий;
включить проверку целостности данных после восстановления и перезапуск сервисов;
мониторинг и уведомления:
настроить систему уведомлений для информирования о статусе резервного копирования и восстановления;
включить отчеты о результатах выполнения резервного копирования и восстановления;
тестирование и проверка:
ежемесячно проводить тестирование процедур восстановления для обеспечения их актуальности и эффективности;
создавать отчеты о тестировании и при необходимости вносить корректировки в процедуры.
Основные этапы#
Этап 1: Подготовка:
установка и настройка ПКД на всех узлах основного и резервного ЦОД;
разработка и тестирование bash-скриптов для резервного копирования.
Этап 2: Настройка репликации:
настройка репликации данных с использованием ПКД и утилит Linux;
тестирование передачи данных между ЦОДами.
Этап 3: Процедуры восстановления:
разработка скриптов для автоматического восстановления баз данных и системного ПО;
тестирование процедур восстановления и проверка их корректности.
Этап 4: Мониторинг и уведомления:
настройка системы уведомлений и отчетов о статусе резервного копирования и восстановления;
внедрение мониторинга для отслеживания состояния систем.
Этап 5: Тестирование и валидация:
ежемесячное тестирование процедур восстановления;
создание отчетов о результатах тестирования и внесение корректировок.
Этап 6: Документация и обучение:
создание документации для всех процедур резервного копирования и восстановления;
обучение команды по использованию и поддержке системы.
Сбор результатов#
После реализации и запуска всех процедур резервного копирования и восстановления необходимо регулярно оценивать их эффективность и соответствие требованиям.
Методы оценки:
отчеты о резервном копировании:
регулярный анализ отчетов о выполнении резервного копирования;
проверка времени выполнения резервного копирования и количества успешных/неуспешных резервных копий;
тестирование восстановления:
ежемесячное тестирование процедур восстановления для проверки их эффективности;
создание отчетов о результатах тестирования, включая время восстановления и целостность данных;
мониторинг и уведомления:
мониторинг системы для выявления проблем в реальном времени;
анализ уведомлений и журналов событий для быстрого реагирования на сбои;
оценка RPO и RTO:
сравнение фактического времени восстановления (RTO) с установленными целями (4 часа);
анализ точек восстановления (RPO) для проверки соответствия целям (8 часов);
обратная связь и улучшение:
сбор обратной связи от команды и пользователей для выявления проблем и предложений по улучшению;
регулярный пересмотр и обновление процедур для поддержания их актуальности и эффективности.
Ключевые показатели:
доля успешных резервных копий;
среднее время восстановления данных и системного ПО;
количество инцидентов, связанных с потерей данных;
время реакции на сбои и проблемы.